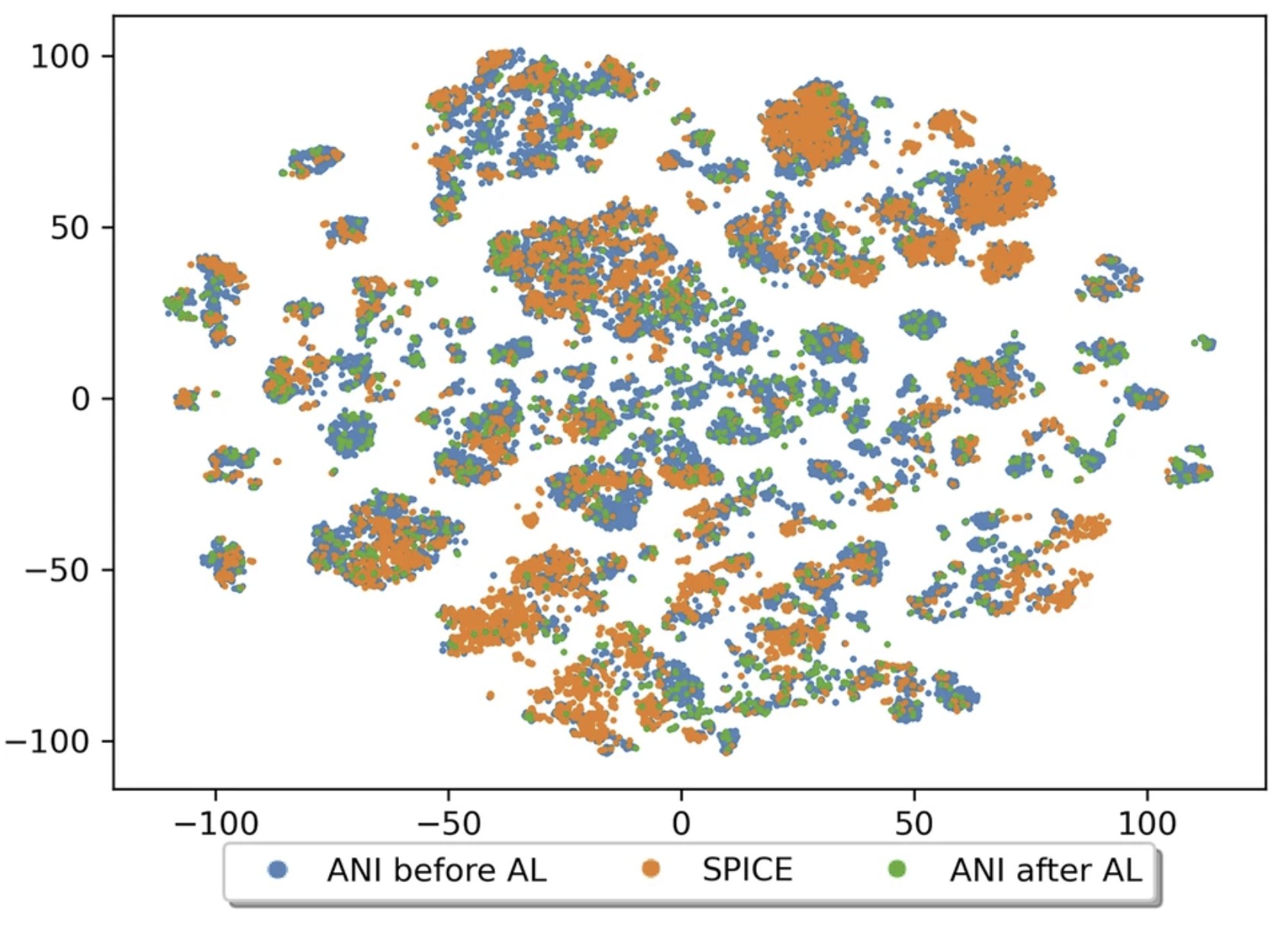
<p>The development of universal machine learning potentials (MLP) for small organic and drug-like molecules requires large, accurate datasets that span diverse chemical spaces. In this study, we introduce the QDπ dataset which incorporates data taken from several datasets. We use a query—by—committee active learning strategy to extract data from large datasets to maximize the diversity and avoid redundancy as relevant for neural network training to construct the QDπ dataset. The QDπ dataset requires only 1.6 million structures to express the chemical diversity of 13 elements from the various source datasets at the ωB97M-D3(BJ)/def2-TZVPPD level of theory. The QDπ dataset enables creation of flexible target loss functions for neural network training relevant to drug discovery, including information-dense data sets of relative conformational energies and barriers, intermolecular interactions, tautomers and relative protonation energies of drug-like compounds and biomolecular fragments. It is the hope that the high chemical information density and diversity contained in the QDπ dataset will provide a valuable resource for the development of new universal MLPs for drug discovery.</p>